

Searching for Style
It’s interesting to watch young children use home assistants. They treat them like people, asking questions like “Alexa, how are you feeling?” and “Alexa, where are you?”. I often wonder what their motivation is. Maybe they don’t know the responses are scripted. Maybe the designers’ choice of which response to script is just as interesting to them as a human’s response would be.
Adults are no less inclined to anthropomorphization — Alexa is marketed as a her and not an it — but they’ve grown used to Alexa’s shortcomings as a conversationalist. Indeed, if you ask them whether they want Alexa to be a better conversation partner, they usually respond with indifference or mild aversion, perhaps recalling a movie like Her and envisioning a society gone too far. But children would be thrilled by the improvement: they haven’t had time to grow to love Alexa for her flaws.
It’s the same with search engines. When someone learns to use Google, they write queries we might consider silly, like “soft kind movie” or “where are the good places?”. It’s because they haven’t yet learned that Google is almost completely silent on matters of taste — try searching for “well-written blog post” and counting the number of well-written blog posts in the results. But if you’re like me, you’ve grown so used to this situation that you don’t see this as a flaw of Google, but rather a result of the user’s innocent inexperience.
To be fair, the problem is hard: what’s “well-written” to one reader might be “Jacob stop using so many commas” to another. And it would be a mistake to assume that a page which advertises itself as well-written is, in fact, well-written. This is different from something like furniture, since it’s more reasonable to trust a page to be honest about whether it contains furniture.
What if we could avoid these difficulties entirely by changing the problem? Instead of requiring the system to determine whether something is well-written, we can give it some writing and ask it to find other writing in the same style. This lets us sidestep the difficult question of defining “good writing”. Instead, we ask the user to provide an example of what they personally view as good writing.
Finding writing “in the same style” might sound just as subjective as finding good writing. But it’s not: if you’re given two sets of documents, and you want to know whether they’re written in the same style, you can test it by training a model to classify which set each document comes from. If it does better than chance, the sets of documents have different styles.
I was curious how this mode of interacting with a search engine would work, so I created a proof of concept.
same.energy
A central constraint when searching for similar style is that the search query needs to have the same form as the content you’re searching for. That means that if you’re looking for music, the query must be music, and if you’re looking for text, the query must be text. To make queries easy to write, I wanted to search for text, and I didn’t want the text to be too long. So I made a search engine for Twitter.
You can try it out at same.energy. It tends to work well when you give it a query that’s long enough (one or two complete sentences). Here’s a video of some queries it does well on:
It’s implemented by using a neural network (RoBERTa-Large, with 355 million parameters) to map each tweet to a vector such that similar tweets have similar vectors (high dot product). When you submit a query, it’s processed by the neural network into a 128-dimensional vector and then matched against all 15,541,670 vectors in the index, without optimizations like locality-sensitive hashing. This is fast enough because it runs on a GPU. (This is light on technical details, and I plan to add more sometime in the future.)
The system has difficulties when people try to use it like a traditional search engine. If you give it a query like “funny tweets”, it won’t search for funny tweets. Instead it will find phrases similar to “funny tweets”, which are mostly nonsense:
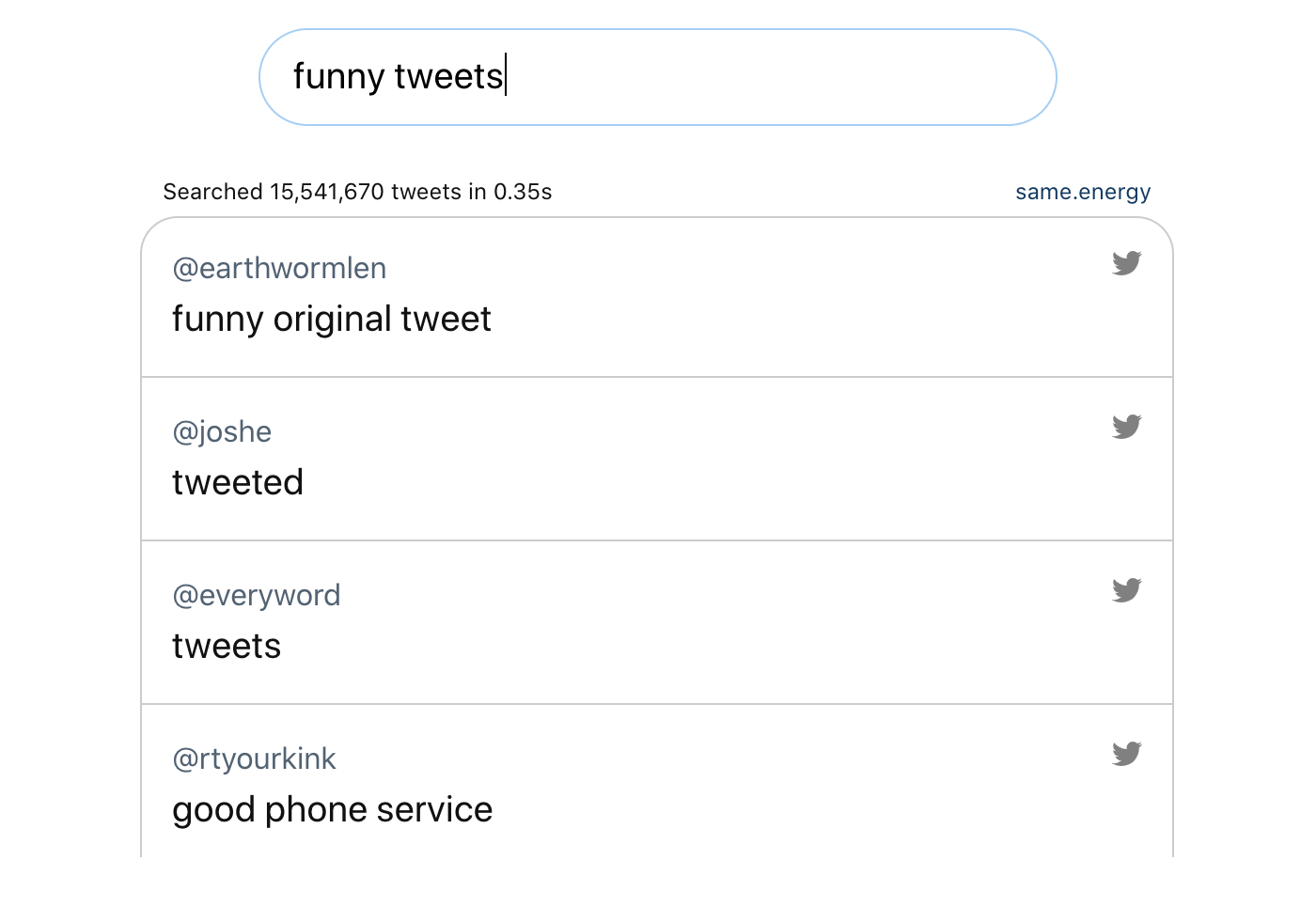
During development, I tried to fix this problem by training the model to match using prefixes of tweets rather than full tweets. This gave better results for short queries because the model would imagine plausible continuations for them and match using those instead. In the end it hurt performance too much on full tweets to be worth it, but it did reveal something interesting: if you asked it to match the style of a tweet starting with “Liberal”, it returned tweets with right-wing opinions. And if you asked it to match the style of a tweet starting with “Conservative”, it returned tweets with left-wing opinions. This suggests that “liberal” and “conservative” are labels more often used by the groups’ opponents than the groups themselves.
Overall, the Twitter search engine was a fun experiment, and it will be nice to see what uses people find for it.
Is this idea new?
The idea of searching by similarity is old. It’s attracted the most interest in the domain of images, where its advantages are clearest. The earliest product I know of is TinEye, released in 2008, which focuses on very close matches. Google introduced reverse image search in 2011. In 2017, Pinterest developed a visual similarity search engine called Lens, which is quite good, especially for finding products given an impromptu photo of the product. (Please contact me if you think there’s anything else I should mention here.)
Recommender systems (such as Netflix’s algorithm) look a lot like similarity search, but they usually use metadata about the objects rather than observing the objects themselves, which means they can’t be queried like a search engine. For example, collaborative filtering uses metadata about who viewed the objects, so you can’t ask it about an object unless it’s already in the database. But the opposite direction works: every similarity search engine can be used as a recommender system.
I think the reason similarity search isn’t widespread yet is because we’ve only recently developed the algorithms and hardware to create a good similarity search engine. My proof of concept uses a transformer, which was only invented in 2018, and it would be too expensive to host in its current form given the cloud computing prices of five years ago (2015).
This is exciting because the technology has great promise. Imagine if upon seeing a beautiful image, piece of music, or passage of text, you could show it to a search engine and see hundreds like it, beautiful in just the same way. I believe this will soon be reality.



