

A Justification of the Cross Entropy Loss
A wise man once told me that inexperienced engineers tend to undervalue simplicity. Since I’m not wise myself, I don’t know whether this is true, but the ideas which show up in many different contexts do seem to be very simple. This post is about two of the most widely used ideas in deep learning, the mean squared error loss and the cross entropy loss, and how in a certain sense they’re the simplest possible approaches.
Let’s start with the mean squared error, which is used when you want to predict a continuous value. If the model’s prediction was 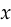 and the correct answer was
and the correct answer was 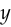 ,
,
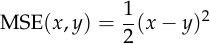
We can observe some basic facts about the mean squared error. It’s differentiable, so we can find its derivative with respect to ,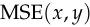 using backpropagation. And it’s zero if and only if
using backpropagation. And it’s zero if and only if 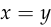 ,
,
But these facts don’t fully explain why people use mean squared error, since there are many other functions which also satisfy both properties. For example, 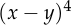 and
and 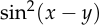
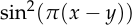 .
.
Instead, we should look at the derivative, which is beautifully simple:
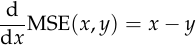
Neither of the alternative functions mentioned above has such a simple derivative. The only function that comes close is 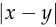 ,
,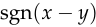 ,
,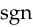 ,
,
So, in plain English, the mean squared error is the loss function you get if you decide that your error signal should be equal to the difference between the output you wanted and the output your model gave. This explains why we should use it: why use anything more complicated if it’s not necessary?
The cross entropy
It turns out that a very similar argument can be used to justify the cross entropy loss. I tried to search for this argument and couldn’t find it anywhere, although it’s straightforward enough that it’s unlikely to be original.
The cross entropy is used when you want to predict a discrete value. To define it, we’ll need to change our framework to make the model output a probability distribution 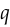 instead of a scalar. The desired output will also be a distribution
instead of a scalar. The desired output will also be a distribution 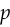 .
.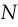 elements which add to 1.
elements which add to 1.
The cross entropy is defined as:
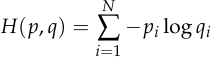
Just like the mean squared error, the cross entropy is differentiable, and it’s minimized if and only if 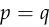 ., instead of itself (where
., instead of itself (where 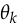 is a model parameter):
is a model parameter):
![\begin{align*} \frac{\partial }{\partial \theta_k} H(p, q) &= \frac{\partial }{\partial \theta_k} \mathbb{E}_{i \sim p} [-\log q_i] \\ &= \mathbb{E}_{i \sim p} \left[\frac{\partial }{\partial \theta_k} (-\log q_i) \right] \end{align*}](/math/193c66ad8e.png)
This is essential for practical use because you don’t typically know the true distribution of labels ).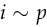 ),
),
But even with the new constraint that the loss function should be linear in ,
So what sets cross entropy apart? To answer this question, let’s make an additional assumption about our model: we assume it produces logits 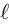 and that its prediction is obtained from using the softmax function:
and that its prediction is obtained from using the softmax function:
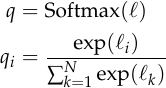
Expressed in terms of ,
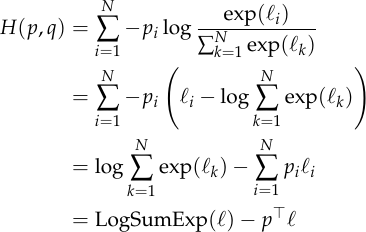
We can now take the gradient with respect to .

So the gradient of 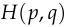 with respect to is:
with respect to is:
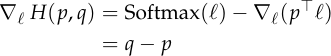
This shows that the cross entropy is just like the mean squared error: its gradient is the difference between the output your model gives )), itself. In this sense, cross entropy is the simplest loss function for classification, just as mean squared error is the simplest for regression.



